2019年5月14日,必赢电子游戏网站张航课题组与李健课题组合作的研究工作“Human representation of multimodal distributions as clusters of samples”在《PLOS Computational Biology》期刊发表。该研究发现人们对于在视觉空间呈现的概率分布会采用样本聚类的方式来进行表征。
在生活中,我们每时每刻都需要处理、加工来自自身和外部环境的不确定性。要加工生活中的不确定性并作出相应的反应,我们需要对概率分布进行表征并进行相关计算。来自前人的行为和神经成像证据均表明,人们的决策行为对分布的特征(如均值、方差、偏度等)是敏感的。但是我们并不清楚,人们具体是如何对分布进行表征的。概率分布中可能发生的事件数量经常是巨大的,且随着分布维度的增加呈指数性增长。因此,人们不可能对于分布中每一个可能发生的事件及其可能性都进行表征,更可能采取了某种近似的策略。
该研究提出,人们可能是采用样本聚类的策略来表征概率分布的。样本聚类的方式具体如下图所示。当人们面对大量来自一个分布的样本时(Samples),会对这些样本进行聚类(Clustering),并只记住聚类后每个类别的中心和相对权重(Representation),以完成对分布信息的简化表征。当需要对分布的特征作出估计时,人们会根据每个类别的中心和相对权重信息来作出相应估计(Estimation)。比如,人们会报告权重最大的类别其中心所在的位置作为对该分布众数的估计,对各类别的中心进行加权平均作为对该分布均值的估计。
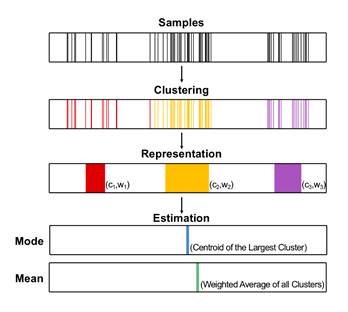
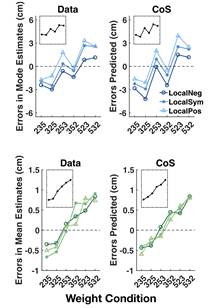
在实验中,研究者在屏幕上一根白色横轴上给被试快速、序列地呈现70根红色的竖线,被试的任务为,在所有竖线呈现完毕后,指出刚才呈现的70根竖线出现最密集的位置(众数)和平均位置(均值)所在。结果发现,被试对于众数和均值的报告均存在系统性偏差(下图左上、左下),表明被试确实可能采取了某种近似策略来表征概率分布。进一步地,作者提出的样本聚类模型(CoS)可以很好地预测出被试估计值的偏差模式(下图右上、右下)。同时,作者总结了前人关于概率分布的多种表征模型,并将这些模型对数据的拟合与该研究中提出的样本聚类模型进行比较,发现样本聚类模型可以比其它模型更好地拟合数据。该研究为样本聚类模型提供强有力的证据支持,对于我们理解人们是如何加工生活中复杂的信息并作出响应有着重要的意义。
必赢电子游戏网站博士研究生孙经纬为该文的第一作者,必赢电子游戏网站、麦戈文脑科学研究所、北大-清华生命科学联合中心张航研究员和必赢电子游戏网站李健研究员为该文的共同通讯作者。该工作由国家自然科学基金、北大-清华生命科学联合中心、中华人民共和国科学技术部资助完成。
2019-05-21